

Trong kỷ nguyên công nghệ 4.0, thuật toán AI đang trở thành một phần không thể thiếu trong nhiều lĩnh vực. Các phương pháp như cây quyết định, máy vector hỗ trợ, học tăng cường và thuật toán di truyền đang được áp dụng rộng rãi để giải quyết các bài toán phức tạp. Cây quyết định giúp phân loại và dự đoán, trong khi máy vector hỗ trợ tối ưu hóa các quyết định. Học tăng cường mang đến khả năng học hỏi từ môi trường, và thuật toán di truyền mô phỏng quá trình tiến hóa tự nhiên để tìm ra giải pháp tối ưu. Hãy cùng khám phá sâu hơn về những thuật toán này!
1. Cây quyết định trong thuật toán AI
Cây quyết định là một trong những thuật toán phổ biến trong lĩnh vực trí tuệ nhân tạo (AI). Nó được sử dụng để phân loại và dự đoán dựa trên các đặc điểm của dữ liệu đầu vào. Cây quyết định hoạt động như một cấu trúc phân nhánh, nơi mỗi nút trong cây đại diện cho một thuộc tính của dữ liệu, và mỗi nhánh đại diện cho một giá trị của thuộc tính đó.
1.1 Nguyên lý hoạt động của cây quyết định
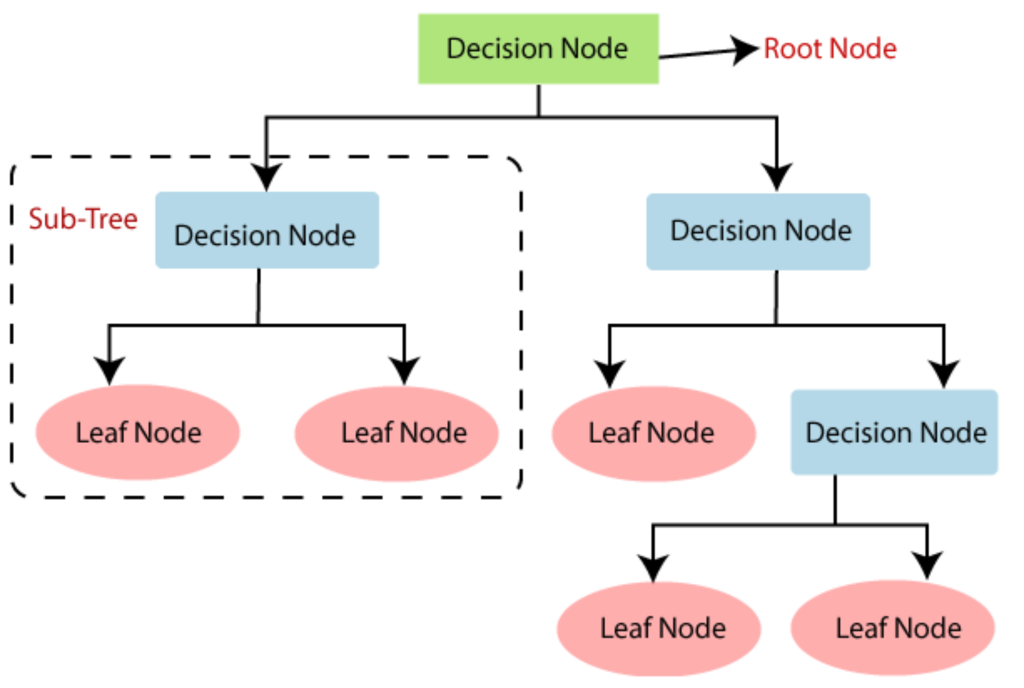
Nguyên lý hoạt động của cây quyết định có thể được mô tả qua các bước sau:
- Chọn thuộc tính: Tại mỗi nút, cây quyết định sẽ chọn thuộc tính tốt nhất để phân chia dữ liệu. Các tiêu chí phổ biến để chọn thuộc tính bao gồm:
- Entropy
- Gini Index
- Chi-squared
- Phân chia dữ liệu: Dựa trên thuộc tính đã chọn, dữ liệu sẽ được phân chia thành các nhánh khác nhau. Mỗi nhánh sẽ đại diện cho một giá trị của thuộc tính đó.
- Lặp lại: Quá trình này sẽ được lặp lại cho từng nhánh cho đến khi đạt được một điều kiện dừng, chẳng hạn như:
- Tất cả các mẫu trong nhánh đều thuộc cùng một lớp.
- Đã đạt đến độ sâu tối đa của cây.
- Dự đoán: Khi cây đã được xây dựng, nó có thể được sử dụng để dự đoán lớp của một mẫu mới bằng cách đi qua cây từ gốc đến lá.
1.2 Ứng dụng trong phân loại và dự đoán
Cây quyết định có nhiều ứng dụng trong các lĩnh vực khác nhau, bao gồm:
- Y tế: Dùng để phân loại bệnh nhân dựa trên các triệu chứng và chỉ số sức khỏe.
- Tài chính: Giúp dự đoán khả năng vỡ nợ của khách hàng dựa trên thông tin tài chính.
- marketing-news/chien-luoc-marketing-hieu-qua-de-tang-truong-doanh-nghiep/”>marketing: Phân tích hành vi khách hàng để xác định các nhóm mục tiêu cho chiến dịch quảng cáo.
| Ứng dụng | Mô tả |
|---|---|
| Y tế | Phân loại bệnh nhân theo triệu chứng và chỉ số sức khỏe. |
| Tài chính | Dự đoán khả năng vỡ nợ dựa trên thông tin tài chính. |
| Marketing | Phân tích hành vi khách hàng để xác định nhóm mục tiêu. |
1.3 Ưu điểm và nhược điểm của cây quyết định
Ưu điểm
- Dễ hiểu và dễ giải thích: Cây quyết định có cấu trúc trực quan, giúp người dùng dễ dàng hiểu và giải thích.
- Không yêu cầu tiền xử lý dữ liệu phức tạp: Cây quyết định có thể làm việc với dữ liệu không chuẩn hóa và không yêu cầu nhiều bước tiền xử lý.
- Có khả năng xử lý cả dữ liệu phân loại và số: Cây quyết định có thể làm việc với cả hai loại dữ liệu này mà không gặp khó khăn.
Nhược điểm
- Dễ bị overfitting: Cây quyết định có thể dễ dàng trở nên quá phức tạp và phù hợp quá mức với dữ liệu huấn luyện.
- Không ổn định: Một thay đổi nhỏ trong dữ liệu có thể dẫn đến một cây quyết định hoàn toàn khác.
- Khó khăn trong việc xử lý dữ liệu lớn: Khi kích thước dữ liệu tăng lên, thời gian và tài nguyên để xây dựng cây quyết định cũng tăng theo.
Tóm lại, cây quyết định là một công cụ mạnh mẽ trong thuật toán AI, nhưng cũng cần được sử dụng một cách cẩn thận để tránh những vấn đề có thể phát sinh.
2. Máy vector hỗ trợ (SVM)
Máy vector hỗ trợ (Support Vector Machine – SVM) là một trong những thuật toán học máy mạnh mẽ và phổ biến nhất hiện nay. Được phát triển vào những năm 1990, SVM được sử dụng rộng rãi trong nhiều lĩnh vực như nhận diện hình ảnh, phân loại văn bản, và phân tích dữ liệu.
Đặc điểm nổi bật của SVM:
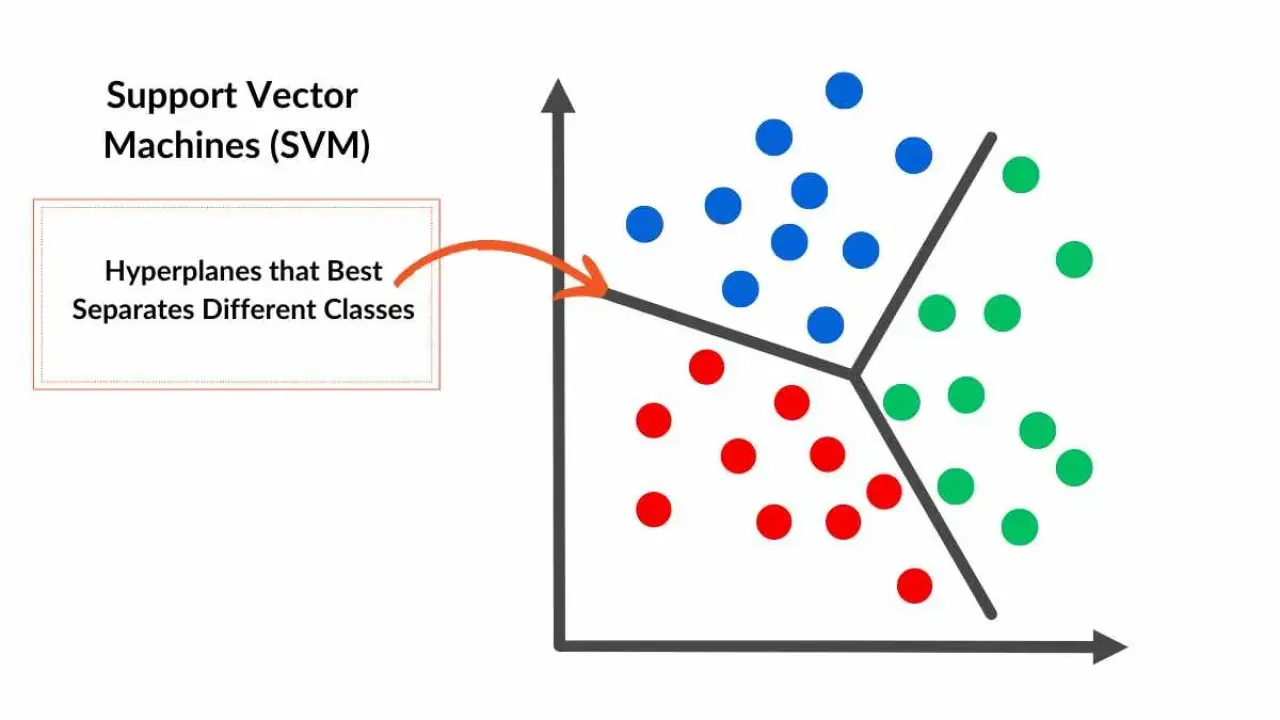
- Phân loại tuyến tính: SVM tìm kiếm một siêu phẳng (hyperplane) tối ưu để phân loại các điểm dữ liệu.
- Khả năng xử lý dữ liệu phi tuyến: SVM có thể sử dụng các hàm kernel để biến đổi dữ liệu phi tuyến thành không gian cao hơn, giúp phân loại dễ dàng hơn.
- Kháng nhiễu: SVM có khả năng chống lại nhiễu và giảm thiểu overfitting thông qua việc tối ưu hóa khoảng cách giữa các điểm dữ liệu và siêu phẳng.
2.1 Cách thức hoạt động của máy vector hỗ trợ
Máy vector hỗ trợ hoạt động dựa trên nguyên lý tìm kiếm siêu phẳng tối ưu trong không gian nhiều chiều. Quá trình này bao gồm các bước chính sau:
- Xác định siêu phẳng: SVM tìm kiếm siêu phẳng có thể phân chia các lớp dữ liệu khác nhau với khoảng cách tối đa từ các điểm dữ liệu đến siêu phẳng.
- Sử dụng hàm kernel: Để xử lý dữ liệu phi tuyến, SVM áp dụng các hàm kernel như RBF (Radial Basis Function), polynomial, hoặc sigmoid để chuyển đổi dữ liệu vào không gian cao hơn.
- Tối ưu hóa: SVM sử dụng các thuật toán tối ưu hóa như phương pháp Lagrange để tìm ra các trọng số tối ưu cho siêu phẳng.
- Dự đoán: Sau khi huấn luyện, SVM có thể dự đoán nhãn cho các điểm dữ liệu mới bằng cách xác định vị trí của chúng so với siêu phẳng.
2.2 Ứng dụng trong nhận diện hình ảnh và văn bản
Máy vector hỗ trợ đã chứng minh được tính hiệu quả của mình trong nhiều ứng dụng thực tiễn, đặc biệt trong lĩnh vực nhận diện hình ảnh và văn bản. Dưới đây là một số ứng dụng tiêu biểu:
| Ứng dụng | Mô tả |
|---|---|
| Nhận diện khuôn mặt | SVM được sử dụng để phân loại và nhận diện khuôn mặt trong các bức ảnh. |
| Phân loại văn bản | SVM có thể phân loại email thành spam và không spam dựa trên nội dung. |
| Nhận diện chữ viết tay | SVM giúp nhận diện chữ viết tay từ hình ảnh, hỗ trợ trong các ứng dụng OCR. |
| Phân tích cảm xúc | SVM có thể phân tích cảm xúc từ văn bản, giúp đánh giá phản hồi của khách hàng. |
2.3 So sánh SVM với các thuật toán khác
Khi so sánh SVM với các thuật toán học máy khác, có một số điểm khác biệt rõ rệt mà người dùng cần lưu ý:
| Thuật toán | Ưu điểm | Nhược điểm |
|---|---|---|
| SVM | – Hiệu suất cao với dữ liệu nhỏ và phức tạp. | – Thời gian huấn luyện lâu với dữ liệu lớn. |
| Cây quyết định | – Dễ hiểu và dễ giải thích. | – Dễ bị overfitting nếu không được điều chỉnh. |
| Học tăng cường | – Tối ưu hóa hiệu suất qua thời gian. | – Cần nhiều dữ liệu và thời gian để huấn luyện. |
| Thuật toán di truyền | – Khả năng tìm kiếm giải pháp tối ưu toàn cục. | – Thời gian tính toán lâu và phức tạp. |
Nhìn chung, SVM là một lựa chọn tuyệt vời cho nhiều bài toán phân loại, nhưng cần cân nhắc đến kích thước và tính chất của dữ liệu để lựa chọn thuật toán phù hợp nhất.
3. Học tăng cường
Học tăng cường (Reinforcement Learning) là một lĩnh vực con của trí tuệ nhân tạo, nơi mà một tác nhân (agent) học cách tối ưu hóa hành động của mình thông qua việc tương tác với môi trường. Tác nhân nhận được phản hồi từ môi trường dưới dạng phần thưởng (reward) hoặc hình phạt (penalty) và từ đó điều chỉnh hành động của mình để tối đa hóa tổng phần thưởng trong thời gian dài.
Đặc điểm chính của học tăng cường:
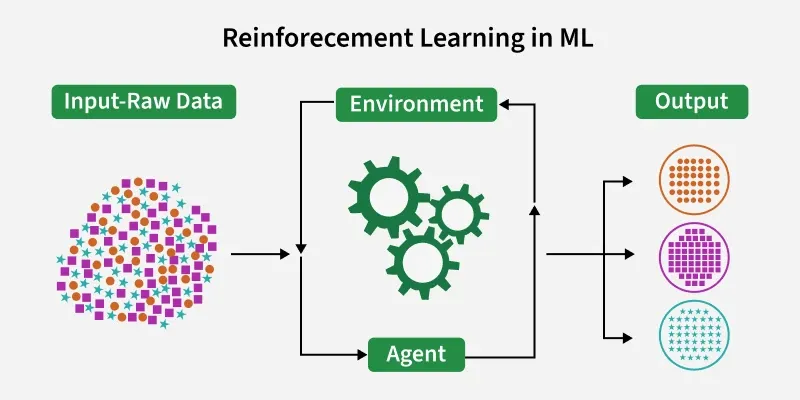
- Tác nhân: Đối tượng thực hiện hành động trong môi trường.
- Môi trường: Nơi mà tác nhân tương tác và nhận phản hồi.
- Phần thưởng: Phản hồi từ môi trường, có thể là tích cực hoặc tiêu cực.
- Chính sách: Chiến lược mà tác nhân sử dụng để quyết định hành động dựa trên trạng thái hiện tại.
Học tăng cường có thể được áp dụng trong nhiều lĩnh vực khác nhau, từ trò chơi điện tử cho đến robot tự hành. Sự phát triển của các thuật toán học sâu (deep learning) đã giúp cải thiện đáng kể hiệu suất của học tăng cường, cho phép các tác nhân học từ dữ liệu lớn và phức tạp.
3.1 Nguyên tắc cơ bản của học tăng cường
Nguyên tắc cơ bản của học tăng cường bao gồm ba thành phần chính: tác nhân, môi trường và chính sách. Tác nhân sẽ thực hiện hành động trong môi trường và nhận phản hồi từ môi trường để điều chỉnh hành động trong tương lai.
Các bước trong quá trình học tăng cường:
- Khởi tạo: Tác nhân bắt đầu ở một trạng thái ban đầu trong môi trường.
- Hành động: Tác nhân chọn một hành động dựa trên chính sách hiện tại.
- Phản hồi: Môi trường cung cấp phản hồi dưới dạng phần thưởng và trạng thái mới.
- Cập nhật: Tác nhân cập nhật chính sách của mình dựa trên phần thưởng nhận được.
Học tăng cường sử dụng các thuật toán như Q-learning và Deep Q-Networks (DQN) để tối ưu hóa chính sách. Các thuật toán này cho phép tác nhân học từ kinh nghiệm và cải thiện hiệu suất theo thời gian.
Bảng so sánh các thuật toán học tăng cường:
| Thuật toán | Đặc điểm nổi bật | Ứng dụng phổ biến |
|---|---|---|
| Q-learning | Không cần mô hình môi trường | Trò chơi đơn giản |
| DQN | Sử dụng mạng nơ-ron sâu để học | Trò chơi phức tạp |
| SARSA | Học chính sách theo cách trực tiếp | Robot tự hành |
| A3C | Học song song nhiều tác nhân | Ứng dụng thực tế phức tạp |
3.2 Ứng dụng trong trò chơi và robot tự hành
Học tăng cường đã chứng minh được giá trị của nó trong nhiều lĩnh vực, đặc biệt là trong trò chơi và robot tự hành. Trong trò chơi, các tác nhân học cách chơi và tối ưu hóa chiến lược để giành chiến thắng.
Ví dụ về ứng dụng trong trò chơi:
- AlphaGo: Sử dụng học tăng cường để đánh bại các kỳ thủ hàng đầu thế giới trong trò chơi cờ vây.
- OpenAI Five: Học cách chơi Dota 2 và thi đấu với các đội tuyển chuyên nghiệp.
Trong lĩnh vực robot tự hành, học tăng cường giúp các robot học cách điều hướng và thực hiện nhiệm vụ trong môi trường thực tế. Các robot có thể học từ kinh nghiệm và cải thiện khả năng hoạt động của mình theo thời gian.
Một số ứng dụng nổi bật:
- Robot giao hàng: Học cách di chuyển trong môi trường đô thị.
- Xe tự lái: Học cách điều khiển và xử lý tình huống giao thông.
3.3 Thách thức và triển vọng tương lai
Mặc dù học tăng cường đã đạt được nhiều thành công, nhưng vẫn còn nhiều thách thức cần phải giải quyết. Một trong những thách thức lớn nhất là việc học từ dữ liệu không đầy đủ hoặc không chính xác.
Một số thách thức chính:
- Tính ổn định: Các thuật toán học tăng cường có thể không ổn định và khó khăn trong việc tối ưu hóa.
- Thời gian học: Quá trình học có thể mất nhiều thời gian và tài nguyên tính toán.
- Khả năng tổng quát: Tác nhân có thể học tốt trong một môi trường nhưng lại không hoạt động hiệu quả trong môi trường khác.
Triển vọng tương lai:
- Tích hợp với học sâu: Kết hợp học tăng cường với các kỹ thuật học sâu để cải thiện khả năng học.
- Ứng dụng trong các lĩnh vực mới: Khám phá các ứng dụng trong y tế, tài chính và sản xuất.
- Phát triển các thuật toán mới: Nghiên cứu và phát triển các thuật toán học tăng cường hiệu quả hơn.
Học tăng cường hứa hẹn sẽ tiếp tục phát triển và mở ra nhiều cơ hội mới trong tương lai, giúp cải thiện khả năng tự động hóa và tối ưu hóa trong nhiều lĩnh vực khác nhau.
4. Thuật toán di truyền
Thuật toán di truyền (Genetic Algorithm – GA) là một phương pháp tối ưu hóa dựa trên nguyên lý chọn lọc tự nhiên và di truyền học. Nó được sử dụng để tìm kiếm giải pháp tối ưu cho các bài toán phức tạp mà không thể giải quyết bằng các phương pháp truyền thống. Thuật toán này hoạt động bằng cách tạo ra một quần thể các cá thể (giải pháp) và tiến hành các phép toán di truyền như chọn lọc, lai ghép và đột biến để cải thiện chất lượng của quần thể qua các thế hệ.
4.1 Nguyên lý hoạt động của thuật toán di truyền
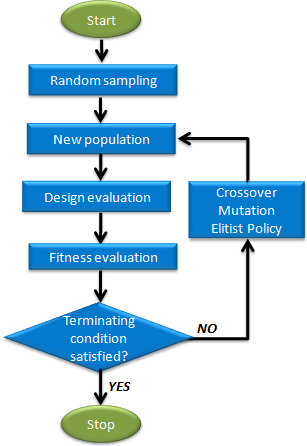
Nguyên lý hoạt động của thuật toán di truyền bao gồm các bước chính sau:
- Khởi tạo quần thể: Bước đầu tiên là tạo ra một quần thể ban đầu gồm nhiều cá thể ngẫu nhiên. Mỗi cá thể đại diện cho một giải pháp khả thi cho bài toán.
- Đánh giá: Mỗi cá thể trong quần thể được đánh giá dựa trên một hàm mục tiêu (fitness function) để xác định chất lượng của nó.
- Chọn lọc: Các cá thể có chất lượng tốt hơn sẽ có khả năng được chọn để sinh sản cao hơn. Phương pháp chọn lọc có thể là chọn lọc tự nhiên, chọn lọc bằng cách quay xổ số, hoặc chọn lọc bằng cách sử dụng tỷ lệ.
- Lai ghép và đột biến: Các cá thể được chọn sẽ được lai ghép để tạo ra thế hệ mới. Bên cạnh đó, một tỷ lệ nhỏ các cá thể sẽ trải qua quá trình đột biến để tạo ra sự đa dạng trong quần thể.
- Lặp lại: Quá trình này sẽ được lặp lại cho đến khi đạt được một giải pháp tối ưu hoặc đạt đến số thế hệ quy định.
4.2 Ứng dụng trong tối ưu hóa và tìm kiếm
Thuật toán di truyền có nhiều ứng dụng trong các lĩnh vực khác nhau, bao gồm:
- Tối ưu hóa hàm: GA có thể được sử dụng để tìm kiếm cực trị của các hàm phức tạp mà không thể giải quyết bằng các phương pháp toán học thông thường.
- Tối ưu hóa thiết kế: Trong kỹ thuật và thiết kế, GA được sử dụng để tối ưu hóa các thông số thiết kế nhằm đạt được hiệu suất tối ưu.
- Tìm kiếm trong không gian lớn: GA rất hiệu quả trong việc tìm kiếm giải pháp trong các không gian lớn và phức tạp, chẳng hạn như trong việc lập lịch, phân bổ tài nguyên, và tối ưu hóa mạng.
- Học máy: Trong lĩnh vực học máy, GA có thể được sử dụng để tối ưu hóa các tham số của mô hình học máy, giúp cải thiện độ chính xác của mô hình.
4.3 So sánh với các phương pháp tối ưu hóa khác
Khi so sánh thuật toán di truyền với các phương pháp tối ưu hóa khác, có một số điểm khác biệt rõ rệt:
| Tiêu chí | Thuật toán di truyền | Phương pháp tối ưu hóa khác |
|---|---|---|
| Khả năng xử lý không gian lớn | Rất tốt | Thường hạn chế |
| Tính đa dạng giải pháp | Cao | Thấp |
| Thời gian tính toán | Có thể lâu | Nhanh hơn trong một số trường hợp |
| Khả năng thoát khỏi cực tiểu địa phương | Tốt | Thường khó khăn |
Nhìn chung, thuật toán di truyền là một công cụ mạnh mẽ trong tối ưu hóa và tìm kiếm, đặc biệt là trong các bài toán phức tạp mà các phương pháp truyền thống không thể giải quyết hiệu quả. Tuy nhiên, việc lựa chọn phương pháp tối ưu hóa phù hợp còn phụ thuộc vào tính chất cụ thể của bài toán và yêu cầu về thời gian









