

Học máy (Machine Learning) là một lĩnh vực quan trọng trong trí tuệ nhân tạo, cho phép máy tính học hỏi từ dữ liệu và cải thiện hiệu suất mà không cần lập trình cụ thể. Trong bài viết này, chúng ta sẽ khám phá hai phương pháp chính của học máy: học có giám sát và thuật toán không giám sát. Học có giám sát sử dụng dữ liệu đào tạo đã được gán nhãn để phân tích dự đoán, giúp máy tính nhận diện mẫu và đưa ra dự đoán chính xác. Ngược lại, thuật toán không giám sát tìm kiếm cấu trúc trong dữ liệu mà không cần thông tin gán nhãn, mở ra nhiều cơ hội mới trong phân tích dữ liệu.
1. Giới thiệu về Học máy
Học máy (Machine Learning) là một lĩnh vực con của trí tuệ nhân tạo (AI) cho phép máy tính học hỏi từ dữ liệu và cải thiện hiệu suất mà không cần lập trình rõ ràng. Học máy đã trở thành một phần quan trọng trong nhiều ứng dụng công nghệ hiện đại, từ nhận diện hình ảnh đến xử lý ngôn ngữ tự nhiên.
1.1 Khái niệm cơ bản về Học máy

Học máy có thể được chia thành ba loại chính:
- Học có giám sát (Supervised Learning): Trong phương pháp này, mô hình được đào tạo trên một tập dữ liệu đã được gán nhãn. Mục tiêu là dự đoán nhãn cho các dữ liệu chưa biết.
- Học không giám sát (Unsupervised Learning): Mô hình học từ dữ liệu không có nhãn, nhằm tìm ra cấu trúc hoặc mẫu trong dữ liệu.
- Học tăng cường (Reinforcement Learning): Mô hình học từ các hành động và phản hồi trong môi trường, tối ưu hóa quyết định dựa trên phần thưởng nhận được.
| Loại Học máy | Đặc điểm chính |
|---|---|
| Học có giám sát | Dữ liệu có nhãn, mục tiêu dự đoán nhãn mới |
| Học không giám sát | Dữ liệu không có nhãn, tìm kiếm cấu trúc |
| Học tăng cường | Học từ phản hồi, tối ưu hóa hành động |
1.2 Lịch sử phát triển và ứng dụng

Học máy đã có một lịch sử phát triển phong phú, bắt đầu từ những năm 1950 với các nghiên cứu đầu tiên về mạng nơ-ron. Dưới đây là một số mốc quan trọng:
- 1950: Alan Turing đề xuất “Turing Test” để đánh giá trí thông minh của máy.
- 1957: Frank Rosenblatt phát triển Perceptron, một trong những mô hình học máy đầu tiên.
- 1980-1990: Sự phát triển của mạng nơ-ron sâu (Deep Learning) bắt đầu thu hút sự chú ý.
- 2000 đến nay: Học máy trở thành một phần không thể thiếu trong nhiều lĩnh vực như y tế, tài chính, và công nghệ thông tin.
Học máy hiện nay được ứng dụng rộng rãi trong nhiều lĩnh vực, bao gồm:
- Y tế: Dự đoán bệnh, phân tích hình ảnh y tế.
- Tài chính: Phân tích rủi ro, phát hiện gian lận.
- Marketing: Phân tích hành vi khách hàng, tối ưu hóa chiến dịch quảng cáo.
1.3 Tầm quan trọng của Học máy trong công nghệ hiện đại
Học máy đóng vai trò quan trọng trong việc cải thiện hiệu suất và khả năng tự động hóa trong nhiều lĩnh vực. Một số lợi ích chính bao gồm:
- Tăng cường hiệu suất: Học máy giúp cải thiện độ chính xác trong dự đoán và phân tích dữ liệu.
- Tiết kiệm thời gian: Tự động hóa các quy trình phân tích dữ liệu, giảm thiểu thời gian và công sức cần thiết.
- Khả năng xử lý dữ liệu lớn: Học máy có khả năng xử lý và phân tích khối lượng dữ liệu lớn mà con người không thể làm được.
| Lợi ích của Học máy | Mô tả |
|---|---|
| Tăng cường hiệu suất | Cải thiện độ chính xác trong dự đoán |
| Tiết kiệm thời gian | Tự động hóa quy trình phân tích dữ liệu |
| Xử lý dữ liệu lớn | Phân tích khối lượng dữ liệu lớn |
Học máy không chỉ là một công nghệ mới mà còn là một công cụ mạnh mẽ giúp các doanh nghiệp và tổ chức tối ưu hóa quy trình làm việc và đưa ra quyết định chính xác hơn.
2. Học có giám sát
Học có giám sát là một trong những phương pháp chính trong lĩnh vực học máy, nơi mà mô hình học từ dữ liệu đã được gán nhãn. Điều này có nghĩa là mỗi mẫu dữ liệu trong tập huấn luyện đều đi kèm với một nhãn hoặc kết quả mong muốn. Mục tiêu của học có giám sát là xây dựng một hàm ánh xạ từ đầu vào (dữ liệu) đến đầu ra (nhãn) sao cho mô hình có thể dự đoán chính xác nhãn cho các dữ liệu chưa thấy.
2.1 Định nghĩa và nguyên lý hoạt động

Học có giám sát hoạt động dựa trên nguyên lý học từ các ví dụ đã biết. Cụ thể, quá trình này bao gồm các bước sau:
- Chuẩn bị dữ liệu: Tập hợp dữ liệu đã được gán nhãn để sử dụng cho việc huấn luyện mô hình.
- Chọn thuật toán: Lựa chọn một thuật toán học máy phù hợp với loại dữ liệu và bài toán.
- Huấn luyện mô hình: Sử dụng dữ liệu đã gán nhãn để huấn luyện mô hình, tối ưu hóa các tham số của nó.
- Dự đoán: Áp dụng mô hình đã huấn luyện để dự đoán nhãn cho dữ liệu mới.
Nguyên lý cốt lõi của học có giám sát là việc sử dụng thông tin từ dữ liệu đã biết để cải thiện khả năng dự đoán cho dữ liệu chưa biết. Điều này giúp mô hình học được các đặc điểm và mối quan hệ trong dữ liệu.
2.2 Các thuật toán phổ biến trong Học có giám sát
Trong học có giám sát, có nhiều thuật toán khác nhau được sử dụng, mỗi thuật toán có những ưu điểm và nhược điểm riêng. Dưới đây là một số thuật toán phổ biến:
| Thuật toán | Mô tả |
|---|---|
| Hồi quy tuyến tính | Sử dụng để dự đoán giá trị liên tục bằng cách tìm mối quan hệ giữa các biến. |
| Cây quyết định | Mô hình hóa quyết định và kết quả bằng cách phân chia dữ liệu thành các nhánh. |
| Máy vector hỗ trợ (SVM) | Tìm kiếm siêu phẳng tối ưu để phân loại dữ liệu thành các nhóm khác nhau. |
| Mạng nơ-ron | Mô hình hóa các mối quan hệ phức tạp thông qua các lớp nơ-ron liên kết. |
Mỗi thuật toán có thể được áp dụng cho các loại bài toán khác nhau, từ phân loại đến hồi quy, và việc lựa chọn thuật toán phù hợp là rất quan trọng trong quá trình phát triển mô hình.
2.3 Ứng dụng thực tiễn của Học có giám sát
Học có giám sát được áp dụng rộng rãi trong nhiều lĩnh vực khác nhau. Dưới đây là một số ứng dụng tiêu biểu:
- Phân loại email: Sử dụng để xác định email nào là spam và email nào là hợp lệ.
- Dự đoán giá bất động sản: Phân tích dữ liệu lịch sử để dự đoán giá của các bất động sản trong tương lai.
- Nhận diện hình ảnh: Phân loại hình ảnh thành các nhóm khác nhau như chó, mèo, xe cộ, v.v.
- Phân tích cảm xúc: Xác định cảm xúc trong văn bản, chẳng hạn như tích cực, tiêu cực hoặc trung tính.
Các ứng dụng này không chỉ giúp cải thiện hiệu suất công việc mà còn tạo ra giá trị lớn cho các doanh nghiệp và tổ chức trong việc ra quyết định. Học có giám sát đang trở thành một công cụ quan trọng trong việc khai thác dữ liệu và tối ưu hóa quy trình làm việc.
3. Thuật toán không giám sát
Thuật toán không giám sát là một nhánh quan trọng trong lĩnh vực học máy, nơi mà các mô hình được đào tạo mà không cần đến nhãn dữ liệu. Điều này có nghĩa là thuật toán sẽ tự động tìm kiếm các mẫu và cấu trúc trong dữ liệu mà không có sự can thiệp của con người. Các ứng dụng của thuật toán không giám sát rất đa dạng, từ phân tích dữ liệu đến nhận diện hình ảnh.
3.1 Khái niệm và cách thức hoạt động
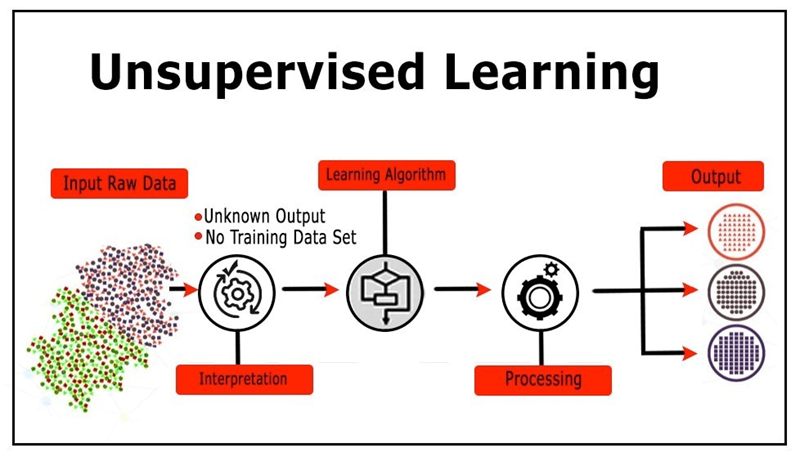
- Khái niệm: Thuật toán không giám sát là một phương pháp học máy mà không yêu cầu dữ liệu được gán nhãn. Mục tiêu chính của nó là khám phá cấu trúc tiềm ẩn trong dữ liệu.
- Cách thức hoạt động:
- Nhập dữ liệu: Dữ liệu đầu vào thường là một tập hợp các đặc trưng mà không có nhãn.
- Tìm kiếm mẫu: Thuật toán sẽ phân tích dữ liệu để tìm kiếm các mẫu, nhóm hoặc cấu trúc.
- Xuất kết quả: Kết quả có thể là các nhóm dữ liệu, các điểm dữ liệu tương tự hoặc các đặc trưng nổi bật.
| Bước | Mô tả |
|---|---|
| 1 | Nhập dữ liệu không có nhãn |
| 2 | Phân tích và tìm kiếm mẫu |
| 3 | Xuất kết quả và đánh giá |
3.2 Các phương pháp phân cụm và phân loại
Có nhiều phương pháp khác nhau trong thuật toán không giám sát, trong đó phân cụm và phân loại là hai phương pháp phổ biến nhất.
- Phân cụm:
- K-Means: Phương pháp phân cụm phổ biến, chia dữ liệu thành k nhóm dựa trên khoảng cách giữa các điểm dữ liệu.
- Hierarchical Clustering: Tạo ra một cây phân cấp để phân loại dữ liệu thành các nhóm.
- Phân loại:
- Autoencoders: Mô hình học sâu giúp giảm chiều dữ liệu và tìm kiếm các đặc trưng chính.
- t-SNE: Phương pháp giảm chiều giúp trực quan hóa dữ liệu trong không gian hai hoặc ba chiều.
| Phương pháp | Mô tả |
|---|---|
| K-Means | Phân cụm dựa trên khoảng cách |
| Hierarchical Clustering | Phân cụm theo cấu trúc phân cấp |
| Autoencoders | Giảm chiều và tìm kiếm đặc trưng |
| t-SNE | Trực quan hóa dữ liệu |
3.3 Lợi ích và thách thức của thuật toán không giám sát
Lợi ích:
- Tiết kiệm thời gian: Không cần gán nhãn dữ liệu, giúp tiết kiệm thời gian và công sức cho người làm dữ liệu.
- Phát hiện mẫu mới: Có khả năng phát hiện các mẫu hoặc cấu trúc mà con người có thể bỏ lỡ.
- Khả năng mở rộng: Có thể áp dụng cho các tập dữ liệu lớn mà không cần thay đổi nhiều.
Thách thức:
- Khó khăn trong việc đánh giá: Không có nhãn để so sánh, việc đánh giá độ chính xác của mô hình trở nên khó khăn.
- Nhạy cảm với dữ liệu: Kết quả có thể bị ảnh hưởng bởi chất lượng và độ chính xác của dữ liệu đầu vào.
- Khó khăn trong việc lựa chọn phương pháp: Có nhiều phương pháp khác nhau, việc lựa chọn phương pháp phù hợp có thể gây khó khăn cho người dùng.
| Lợi ích | Thách thức |
|---|---|
| Tiết kiệm thời gian | Khó khăn trong việc đánh giá |
| Phát hiện mẫu mới | Nhạy cảm với dữ liệu |
| Khả năng mở rộng | Khó khăn trong việc lựa chọn |
4. Phân tích dự đoán và tối ưu hóa dữ liệu đào tạo
Phân tích dự đoán là một lĩnh vực quan trọng trong học máy, giúp các tổ chức và doanh nghiệp dự đoán các xu hướng và hành vi trong tương lai dựa trên dữ liệu hiện có. Quá trình này không chỉ giúp cải thiện quyết định kinh doanh mà còn tối ưu hóa quy trình làm việc. Để thực hiện phân tích dự đoán hiệu quả, cần có một bộ dữ liệu đào tạo chất lượng cao và các thuật toán phù hợp.
Lợi ích của phân tích dự đoán:
- Dự đoán xu hướng: Giúp xác định các xu hướng trong dữ liệu để đưa ra quyết định kịp thời.
- Tối ưu hóa quy trình: Cải thiện hiệu suất và giảm thiểu rủi ro trong các hoạt động kinh doanh.
- Tăng cường trải nghiệm khách hàng: Dự đoán nhu cầu của khách hàng để cải thiện dịch vụ và sản phẩm.
- Tiết kiệm chi phí: Giảm thiểu lãng phí thông qua việc tối ưu hóa nguồn lực.
Để đạt được những lợi ích này, việc tối ưu hóa dữ liệu đào tạo là rất cần thiết. Dữ liệu đào tạo không chỉ cần đầy đủ mà còn phải chính xác và có tính đại diện cao.
4.1 Khái niệm về phân tích dự đoán

Phân tích dự đoán là quá trình sử dụng các thuật toán và mô hình thống kê để dự đoán các kết quả tương lai dựa trên dữ liệu lịch sử. Trong học máy, phân tích dự đoán thường được thực hiện thông qua các phương pháp học có giám sát, nơi mà mô hình được huấn luyện trên một tập dữ liệu đã được gán nhãn.
Các bước trong phân tích dự đoán:
- Thu thập dữ liệu: Tìm kiếm và thu thập dữ liệu từ các nguồn khác nhau.
- Tiền xử lý dữ liệu: Làm sạch và chuẩn hóa dữ liệu để đảm bảo chất lượng.
- Chọn mô hình: Lựa chọn thuật toán phù hợp cho bài toán dự đoán.
- Đánh giá mô hình: Sử dụng các chỉ số như độ chính xác, độ nhạy để đánh giá hiệu suất của mô hình.
Phân tích dự đoán có thể được áp dụng trong nhiều lĩnh vực như tài chính, marketing, y tế và nhiều lĩnh vực khác. Việc hiểu rõ về khái niệm này là rất quan trọng để áp dụng hiệu quả trong thực tế.
4.2 Cách tối ưu hóa dữ liệu đào tạo
Tối ưu hóa dữ liệu đào tạo là một bước quan trọng trong quá trình xây dựng mô hình học máy. Dữ liệu không chỉ cần đầy đủ mà còn phải chính xác và có tính đại diện cao để mô hình có thể học hỏi và dự đoán chính xác.
Một số phương pháp tối ưu hóa dữ liệu:
- Làm sạch dữ liệu: Xóa bỏ các giá trị thiếu, lỗi hoặc không hợp lệ.
- Chọn lựa đặc trưng: Lựa chọn các đặc trưng quan trọng nhất để giảm thiểu độ phức tạp của mô hình.
- Tăng cường dữ liệu: Sử dụng các kỹ thuật như xoay, lật, hoặc thêm nhiễu để tạo ra nhiều mẫu dữ liệu hơn.
- Chia tách dữ liệu: Chia dữ liệu thành các tập huấn luyện, kiểm tra và xác thực để đánh giá mô hình.
Việc tối ưu hóa dữ liệu đào tạo không chỉ giúp cải thiện độ chính xác của mô hình mà còn giảm thiểu thời gian và chi phí trong quá trình phát triển.
4.3 Các công cụ và kỹ thuật hỗ trợ phân tích dự đoán
Để thực hiện phân tích dự đoán hiệu quả, có nhiều công cụ và kỹ thuật hỗ trợ mà các nhà phân tích và nhà khoa học dữ liệu có thể sử dụng. Những công cụ này giúp tự động hóa quy trình phân tích và tối ưu hóa mô hình.
Một số công cụ phổ biến:
| Công cụ | Mô tả |
|---|---|
| Python | Ngôn ngữ lập trình phổ biến với nhiều thư viện hỗ trợ học máy như Scikit-learn, TensorFlow. |
| R | Ngôn ngữ lập trình mạnh mẽ cho phân tích thống kê và học máy. |
| Tableau | Công cụ trực quan hóa dữ liệu giúp phân tích và trình bày dữ liệu một cách trực quan. |
| RapidMiner | Nền tảng phân tích dữ liệu mạnh mẽ với giao diện thân thiện cho người dùng. |
Kỹ thuật hỗ trợ:
- Học có giám sát: Sử dụng dữ liệu đã gán nhãn để huấn luyện mô hình.
- Học không giám sát: Phân tích dữ liệu mà không cần gán nhãn, giúp phát hiện các mẫu và cấu trúc trong dữ liệu.
- Phân tích hồi quy: Sử dụng để dự đoán giá trị liên tục dựa trên các biến độc lập.
- Cây quyết định: Mô hình hóa quyết định và kết quả dựa trên các đặc trưng của dữ liệu.
Sự kết hợp giữa các công cụ và kỹ thuật này sẽ giúp nâng cao khả năng phân tích dự đoán và tối ưu hóa dữ liệu đào tạo, từ đó cải thiện









