

Học sâu (Deep Learning) đã trở thành một trong những lĩnh vực nổi bật trong trí tuệ nhân tạo, với khả năng xử lý và phân tích dữ liệu phức tạp. Các lớp mạng nơ-ron, đặc biệt là mạng tích chập (Convolutional Neural Networks), đóng vai trò quan trọng trong việc nhận diện hình ảnh và xử lý ngữ liệu. Kiến trúc nơ-ron sâu (Deep Neural Architecture) cho phép mô hình học được các đặc trưng phức tạp từ dữ liệu. Để tối ưu hóa hiệu suất của các mô hình này, phương pháp tối ưu hóa gradient descent được sử dụng rộng rãi, giúp cải thiện độ chính xác và tốc độ học của mạng nơ-ron.
1. Giới thiệu về Học Sâu
Học sâu (Deep Learning) là một lĩnh vực con của học máy (Machine Learning) và trí tuệ nhân tạo (Artificial Intelligence). Nó sử dụng các mô hình mạng nơ-ron để học từ dữ liệu lớn, giúp máy tính có khả năng tự động nhận diện và phân loại thông tin. Học sâu đã trở thành một công cụ mạnh mẽ trong nhiều lĩnh vực, từ nhận diện hình ảnh đến xử lý ngôn ngữ tự nhiên.
Các lớp mạng nơ-ron
Học sâu chủ yếu dựa vào các lớp mạng nơ-ron, bao gồm:
- Mạng nơ-ron đơn giản: Chỉ có một lớp đầu vào và một lớp đầu ra.
- Mạng nơ-ron nhiều lớp: Bao gồm nhiều lớp ẩn, cho phép mô hình học được các đặc trưng phức tạp hơn.
- Mạng tích chập (Convolutional Neural Networks – CNN): Đặc biệt hiệu quả trong nhận diện hình ảnh.
- Mạng hồi tiếp (Recurrent Neural Networks – RNN): Thích hợp cho dữ liệu tuần tự như văn bản hoặc âm thanh.
1.1 Khái niệm cơ bản về học sâu

Học sâu sử dụng các mạng nơ-ron sâu, nơi mà mỗi nơ-ron trong một lớp sẽ kết nối với nhiều nơ-ron trong lớp tiếp theo. Điều này cho phép mô hình học được các đặc trưng phức tạp từ dữ liệu đầu vào. Một số khái niệm cơ bản bao gồm:
- Nơ-ron: Đơn vị cơ bản của mạng nơ-ron, tương tự như tế bào thần kinh trong não người.
- Hàm kích hoạt: Quyết định xem nơ-ron có được kích hoạt hay không, phổ biến là hàm ReLU, Sigmoid, và Tanh.
- Học có giám sát và không có giám sát: Học có giám sát sử dụng dữ liệu đã được gán nhãn, trong khi học không có giám sát không cần nhãn.
1.2 Lịch sử phát triển của học sâu
Học sâu đã có một lịch sử phát triển dài, bắt đầu từ những năm 1950. Một số cột mốc quan trọng bao gồm:
| Năm | Sự kiện |
|---|---|
| 1958 | Frank Rosenblatt phát triển Perceptron. |
| 1986 | David Rumelhart, Geoffrey Hinton, và Ronald Williams giới thiệu thuật toán lan truyền ngược (Backpropagation). |
| 2012 | Mạng nơ-ron sâu giành chiến thắng trong cuộc thi ImageNet. |
| 2015 | Học sâu trở thành xu hướng chính trong AI. |
Sự phát triển của phần cứng và dữ liệu lớn đã thúc đẩy sự tiến bộ của học sâu, giúp nó trở thành một trong những lĩnh vực nghiên cứu hàng đầu hiện nay.
1.3 Ứng dụng của học sâu trong thực tế
Học sâu đã được áp dụng rộng rãi trong nhiều lĩnh vực khác nhau. Một số ứng dụng tiêu biểu bao gồm:
- Nhận diện hình ảnh: Sử dụng mạng tích chập để phân loại và nhận diện đối tượng trong hình ảnh.
- Xử lý ngôn ngữ tự nhiên: Áp dụng mạng hồi tiếp để phân tích và sinh ngôn ngữ.
- Xe tự lái: Học sâu giúp nhận diện và phản ứng với môi trường xung quanh.
- Y tế: Phân tích hình ảnh y tế để phát hiện bệnh.
Học sâu không chỉ cải thiện hiệu suất trong các nhiệm vụ cụ thể mà còn mở ra nhiều cơ hội mới cho nghiên cứu và phát triển công nghệ.
2. Các lớp mạng nơ-ron
Mạng nơ-ron là một trong những công nghệ cốt lõi trong học sâu, cho phép máy tính học từ dữ liệu một cách hiệu quả. Các lớp mạng nơ-ron được cấu trúc thành nhiều tầng, mỗi tầng có nhiệm vụ xử lý thông tin và truyền đạt kết quả cho tầng tiếp theo. Dưới đây là một số điểm quan trọng về các lớp mạng nơ-ron:
- Cấu trúc đa tầng: Mạng nơ-ron thường bao gồm ba loại lớp chính: lớp đầu vào, lớp ẩn và lớp đầu ra.
- Lớp đầu vào: Nhận dữ liệu đầu vào và chuyển đổi chúng thành định dạng mà mạng có thể xử lý.
- Lớp ẩn: Chứa nhiều nơ-ron, thực hiện các phép toán phức tạp để trích xuất đặc trưng từ dữ liệu.
- Lớp đầu ra: Cung cấp kết quả cuối cùng của mạng nơ-ron, có thể là phân loại, dự đoán hoặc bất kỳ loại đầu ra nào khác.
Mỗi lớp trong mạng nơ-ron có vai trò riêng biệt và ảnh hưởng đến hiệu suất của mô hình. Việc thiết kế các lớp này một cách hợp lý là rất quan trọng để đạt được kết quả tốt nhất trong học sâu.
2.1 Mạng nơ-ron đơn giản và cấu trúc của nó
Mạng nơ-ron đơn giản thường bao gồm một lớp đầu vào, một lớp ẩn và một lớp đầu ra. Cấu trúc này giúp dễ dàng hiểu và triển khai, đặc biệt cho những người mới bắt đầu với học sâu. Dưới đây là một số đặc điểm của mạng nơ-ron đơn giản:
- Lớp đầu vào: Nhận các đặc trưng từ dữ liệu, ví dụ như pixel trong hình ảnh.
- Lớp ẩn: Thực hiện các phép toán phi tuyến tính để tìm ra mối quan hệ giữa các đặc trưng.
- Lớp đầu ra: Đưa ra dự đoán hoặc phân loại dựa trên các đặc trưng đã được xử lý.
Bảng so sánh cấu trúc mạng nơ-ron đơn giản:
| Thành phần | Chức năng |
|---|---|
| Lớp đầu vào | Nhận dữ liệu đầu vào |
| Lớp ẩn | Xử lý và trích xuất đặc trưng |
| Lớp đầu ra | Cung cấp kết quả cuối cùng |
Mặc dù mạng nơ-ron đơn giản có thể giải quyết nhiều bài toán, nhưng chúng thường không đủ mạnh để xử lý các tác vụ phức tạp hơn. Do đó, các kiến trúc mạng nơ-ron sâu hơn đã được phát triển để cải thiện khả năng học của máy.
2.2 Các loại lớp trong mạng nơ-ron

Trong mạng nơ-ron, có nhiều loại lớp khác nhau, mỗi loại có chức năng và ứng dụng riêng. Dưới đây là một số loại lớp phổ biến:
- Lớp tích chập (Convolutional Layer):
- Sử dụng trong mạng nơ-ron tích chập (CNN) để xử lý dữ liệu hình ảnh.
- Giúp phát hiện các đặc trưng không gian như cạnh, góc và hình dạng.
- Lớp nơ-ron đầy đủ (Fully Connected Layer):
- Mỗi nơ-ron trong lớp này kết nối với tất cả nơ-ron trong lớp trước đó.
- Thường được sử dụng ở cuối mạng để tổng hợp thông tin.
- Lớp hồi tiếp (Recurrent Layer):
- Sử dụng trong mạng nơ-ron hồi tiếp (RNN) để xử lý dữ liệu theo chuỗi.
- Thích hợp cho các bài toán như dịch ngôn ngữ và phân tích chuỗi thời gian.
- Lớp chuẩn hóa (Normalization Layer):
- Giúp cải thiện tốc độ học và độ chính xác của mạng.
- Ví dụ: Lớp chuẩn hóa Batch Normalization.
Bảng tóm tắt các loại lớp:
| Loại lớp | Chức năng | Ứng dụng |
|---|---|---|
| Lớp tích chập | Phát hiện đặc trưng không gian | Nhận diện hình ảnh |
| Lớp nơ-ron đầy đủ | Tổng hợp thông tin | Phân loại |
| Lớp hồi tiếp | Xử lý dữ liệu theo chuỗi | Dịch ngôn ngữ |
| Lớp chuẩn hóa | Cải thiện tốc độ học | Tăng cường độ chính xác |
Mỗi loại lớp có những ưu điểm và nhược điểm riêng, và việc lựa chọn loại lớp phù hợp là rất quan trọng trong việc thiết kế mạng nơ-ron.
2.3 Vai trò của các lớp trong việc học
Các lớp trong mạng nơ-ron đóng vai trò quan trọng trong việc học và tối ưu hóa mô hình. Chúng giúp mạng nơ-ron trích xuất và xử lý thông tin từ dữ liệu đầu vào một cách hiệu quả. Dưới đây là một số vai trò chính của các lớp:
- Trích xuất đặc trưng: Các lớp ẩn giúp mạng nơ-ron tìm ra các đặc trưng quan trọng từ dữ liệu, từ đó cải thiện khả năng dự đoán.
- Giảm thiểu độ phức tạp: Các lớp có thể giúp giảm thiểu độ phức tạp của dữ liệu, giúp mạng dễ dàng học hơn.
- Tối ưu hóa mô hình: Các lớp khác nhau có thể được kết hợp để tối ưu hóa mô hình cho các tác vụ cụ thể, như phân loại hoặc hồi quy.
Lợi ích của việc sử dụng nhiều lớp:
| Lợi ích | Mô tả |
|---|---|
| Tăng cường khả năng học | Nhiều lớp giúp mạng học được nhiều đặc trưng phức tạp hơn. |
| Cải thiện độ chính xác | Các lớp có thể giúp giảm thiểu sai số dự đoán. |
| Đa dạng hóa mô hình | Có thể kết hợp nhiều loại lớp để giải quyết các bài toán khác nhau. |
Việc thiết kế và tối ưu hóa các lớp trong mạng nơ-ron là một trong những yếu tố quyết định đến thành công của mô hình học sâu. Các nhà nghiên cứu và kỹ sư thường phải thử nghiệm và điều chỉnh các lớp để đạt được hiệu suất tốt nhất.
3. Mạng tích chập (CNN)
Mạng tích chập (Convolutional Neural Network – CNN) là một trong những kiến trúc mạng nơ-ron được sử dụng phổ biến trong lĩnh vực học sâu, đặc biệt là trong nhận diện hình ảnh và xử lý tín hiệu. CNN được thiết kế để tự động phát hiện các đặc trưng trong dữ liệu hình ảnh mà không cần phải thực hiện các bước tiền xử lý phức tạp.
Đặc điểm nổi bật của CNN:
- Tính đồng nhất: CNN sử dụng các lớp tích chập để xử lý dữ liệu, giúp giảm thiểu số lượng tham số cần thiết.
- Khả năng phát hiện đặc trưng: Các lớp tích chập có khả năng phát hiện các đặc trưng khác nhau từ hình ảnh, từ các đường nét đơn giản đến các hình dạng phức tạp.
- Khả năng tổng quát: CNN có khả năng tổng quát tốt hơn so với các mạng nơ-ron truyền thống nhờ vào việc sử dụng các lớp pooling.
3.1 Nguyên lý hoạt động của mạng tích chập
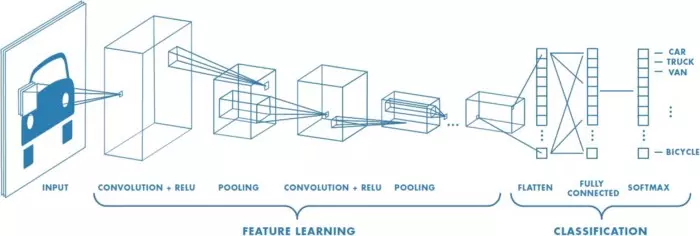
Nguyên lý hoạt động của mạng tích chập dựa trên việc sử dụng các lớp tích chập để trích xuất đặc trưng từ dữ liệu đầu vào. Quá trình này thường bao gồm các bước sau:
- Lớp tích chập: Dữ liệu đầu vào (hình ảnh) được đưa qua các bộ lọc (kernel) để tạo ra các bản đồ đặc trưng (feature maps).
- Lớp kích hoạt: Sau khi có các bản đồ đặc trưng, một hàm kích hoạt (như ReLU) được áp dụng để tăng cường tính phi tuyến.
- Lớp pooling: Lớp này giúp giảm kích thước của bản đồ đặc trưng, từ đó giảm thiểu số lượng tham số và tính toán.
- Lớp fully connected: Cuối cùng, các bản đồ đặc trưng được đưa vào các lớp fully connected để thực hiện phân loại.
| Bước | Mô tả |
|---|---|
| 1 | Lớp tích chập: Tạo bản đồ đặc trưng |
| 2 | Lớp kích hoạt: Tăng cường tính phi tuyến |
| 3 | Lớp pooling: Giảm kích thước bản đồ |
| 4 | Lớp fully connected: Phân loại |
3.2 Ứng dụng của CNN trong nhận diện hình ảnh
CNN đã được áp dụng rộng rãi trong nhiều lĩnh vực khác nhau, đặc biệt là trong nhận diện hình ảnh. Dưới đây là một số ứng dụng tiêu biểu:
- Nhận diện khuôn mặt: CNN có thể nhận diện và phân loại khuôn mặt trong các bức ảnh, giúp cải thiện bảo mật và trải nghiệm người dùng.
- Phân loại hình ảnh: CNN có khả năng phân loại hình ảnh thành các danh mục khác nhau, từ động vật, thực vật đến các đối tượng khác.
- Phát hiện đối tượng: CNN có thể được sử dụng để phát hiện các đối tượng trong hình ảnh, như ô tô, người đi bộ, và các vật thể khác.
- Xử lý video: CNN cũng có thể được áp dụng trong việc phân tích video, giúp nhận diện các hành động và sự kiện trong thời gian thực.
3.3 So sánh CNN với các loại mạng khác
Khi so sánh CNN với các loại mạng nơ-ron khác, ta có thể nhận thấy một số điểm khác biệt rõ rệt:
| Tiêu chí | CNN | Mạng nơ-ron truyền thống |
|---|---|---|
| Cấu trúc | Sử dụng lớp tích chập và pooling | Sử dụng lớp fully connected |
| Tính toán | Giảm thiểu số lượng tham số | Thường có nhiều tham số hơn |
| Khả năng phát hiện đặc trưng | Tự động phát hiện đặc trưng | Cần phải thiết kế đặc trưng thủ công |
| Ứng dụng | Tốt cho nhận diện hình ảnh và video | Tốt cho dữ liệu có cấu trúc như bảng |
4. Kiến trúc nơ-ron sâu
Kiến trúc nơ-ron sâu (Deep Neural Networks – DNN) là một trong những khía cạnh quan trọng nhất trong lĩnh vực học sâu (Deep Learning). Nó bao gồm nhiều lớp nơ-ron, cho phép mô hình học được các đặc trưng phức tạp từ dữ liệu. Kiến trúc này đã được áp dụng rộng rãi trong nhiều lĩnh vực như nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên và nhiều ứng dụng khác.
Các thành phần chính của kiến trúc nơ-ron sâu:

- Lớp đầu vào: Nhận dữ liệu đầu vào và chuyển đổi chúng thành định dạng mà mô hình có thể xử lý.
- Lớp ẩn: Nơi mà các phép toán nơ-ron diễn ra, có thể có nhiều lớp ẩn tùy thuộc vào độ sâu của mô hình.
- Lớp đầu ra: Cung cấp kết quả cuối cùng của mô hình, có thể là phân loại hoặc dự đoán giá trị.
Kiến trúc nơ-ron sâu có thể được điều chỉnh để phù hợp với từng loại dữ liệu và bài toán cụ thể, từ đó tối ưu hóa hiệu suất của mô hình.
4.1 Các kiến trúc phổ biến trong học sâu
Trong học sâu, có một số kiến trúc nơ-ron phổ biến mà các nhà nghiên cứu và kỹ sư thường sử dụng:
- Mạng tích chập (Convolutional Neural Networks – CNN):
- Thích hợp cho các bài toán nhận diện hình ảnh.
- Sử dụng các lớp tích chập để phát hiện các đặc trưng không gian trong dữ liệu hình ảnh.
- Mạng hồi tiếp (Recurrent Neural Networks – RNN):
- Phù hợp cho các bài toán xử lý chuỗi như ngôn ngữ tự nhiên.
- Có khả năng ghi nhớ thông tin từ các bước trước đó trong chuỗi.
- Mạng nơ-ron đối kháng (Generative Adversarial Networks – GAN):
- Được sử dụng để tạo ra dữ liệu mới từ dữ liệu đã học.
- Gồm hai mạng: mạng sinh (Generator) và mạng phân biệt (Discriminator).
- Mạng nơ-ron sâu (Deep Belief Networks – DBN):
- Kết hợp nhiều lớp nơ-ron để học các đặc trưng phức tạp.
- Thường được sử dụng trong các bài toán phân loại và nhận diện.
| Kiến trúc | Ứng dụng chính |
|---|---|
| CNN | Nhận diện hình ảnh |
| RNN | Xử lý ngôn ngữ tự nhiên |
| GAN | Tạo dữ liệu mới |
| DBN | Phân loại và nhận diện |
4.2 Tối ưu hóa kiến trúc để nâng cao hiệu suất
Tối ưu hóa kiến trúc nơ-ron sâu là một trong những bước quan trọng để nâng cao hiệu suất của mô hình. Dưới đây là một số phương pháp tối ưu hóa phổ biến:
- Chọn số lượng lớp và số lượng nơ-ron: Số lượng lớp và nơ-ron trong mỗi lớp cần được điều chỉnh để tránh hiện tượng overfitting hoặc underfitting.
- Sử dụng các kỹ thuật regularization: Như Dropout hoặc L2 regularization để ngăn chặn mô hình học quá nhiều từ dữ liệu huấn luyện.
- Tuning hyperparameters: Điều chỉnh các tham số như learning rate, batch size, và số epoch để đạt được hiệu suất tốt nhất.
- Sử dụng các optimizer hiện đại: Như Adam, RMSprop để cải thiện tốc độ hội tụ của mô hình.
| Phương pháp tối ưu hóa | Mô tả |
|---|---|
| Chọn số lượng lớp | Điều chỉnh số lượng lớp và nơ-ron |
| Regularization | Sử dụng Dropout hoặc L2 regularization |
| Tuning hyperparameters | Điều chỉnh learning rate, batch size |
| Sử dụng optimizer | Áp dụng Adam, RMSprop cho tốc độ hội tụ |
4.3 Thách thức trong việc thiết kế kiến trúc nơ-ron sâu
Mặc dù kiến trúc nơ-ron sâu mang lại nhiều lợi ích, nhưng cũng gặp phải một số thách thức trong quá trình thiết kế:
- Overfitting: Khi mô hình học quá nhiều từ dữ liệu huấn luyện, dẫn đến hiệu suất kém trên dữ liệu kiểm tra. Điều này thường xảy ra khi mô hình quá phức tạp.
- Vanishing Gradient: Khi gradient trở nên rất nhỏ trong quá trình huấn luyện, làm cho việc cập nhật trọng số trở nên khó khăn. Điều này thường xảy ra trong các mạng nơ-ron sâu với nhiều lớp.
- Yêu cầu tính toán cao: Các mô hình nơ-ron sâu yêu cầu tài nguyên tính toán lớn, điều này có thể gây khó khăn cho việc triển khai trên các thiết bị có giới hạn về phần cứng.
- Khó khăn trong việc lựa chọn kiến trúc: Việc tìm ra kiến trúc tối ưu cho một bài toán cụ thể có thể mất nhiều thời gian và công sức, do có quá nhiều biến thể và lựa chọn.
| Thách thức | Giải pháp |
|---|---|
| Overfitting | Sử dụng regularization và tăng dữ liệu |
| Vanishing Gradient | Sử dụng các hàm kích hoạt như ReLU |
| Yêu cầu tính toán cao | Sử dụng GPU hoặc TPU để tăng tốc độ tính toán |
| Khó khăn trong lựa chọn | Thử nghiệm nhiều kiến trúc khác nhau |
5. Tối ưu hóa gradient descent
Tối ưu hóa gradient descent là một trong những phương pháp quan trọng nhất trong học sâu, giúp tối ưu hóa các tham số của mô hình để giảm thiểu hàm mất mát. Phương pháp này hoạt động dựa trên nguyên lý tính toán gradient (đạo hàm) của hàm mất mát đối với các tham số, từ đó điều chỉnh các tham số theo hướng giảm thiểu hàm mất mát.
Các bước thực hiện gradient descent:
- Khởi tạo tham số: Bắt đầu với các giá trị ngẫu nhiên cho các tham số của mô hình.
- Tính toán gradient: Tính toán gradient của hàm mất mát tại điểm hiện tại.
- Cập nhật tham số: Điều chỉnh các tham số theo hướng ngược lại với gradient, với một tỷ lệ học (learning rate) nhất định.
- Lặp lại: Lặp lại quá trình này cho đến khi hàm mất mát đạt được giá trị tối ưu hoặc không còn thay đổi nhiều.
Tối ưu hóa gradient descent có thể được áp dụng cho nhiều loại mô hình khác nhau, từ mạng nơ-ron đơn giản đến các kiến trúc phức tạp hơn.
5.1 Nguyên lý hoạt động của gradient descent
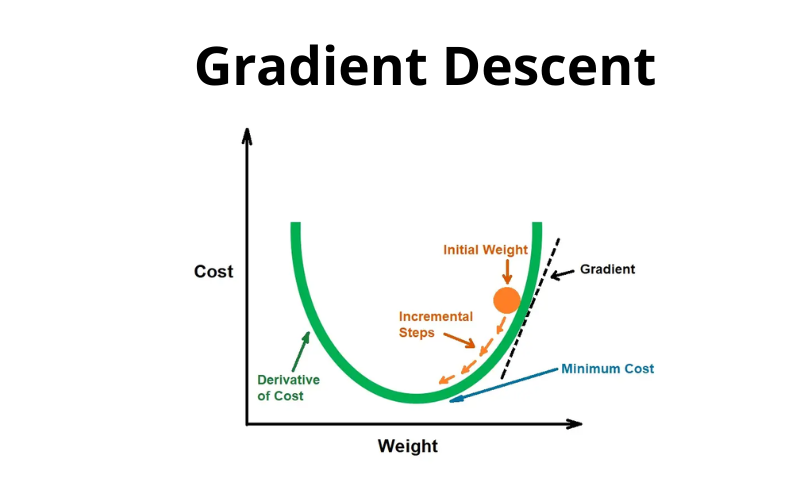
Nguyên lý hoạt động của gradient descent dựa trên việc sử dụng đạo hàm để tìm ra hướng đi tốt nhất cho việc tối ưu hóa. Cụ thể, gradient của hàm mất mát cho biết hướng mà hàm mất mát tăng lên, do đó, để giảm thiểu hàm mất mát, chúng ta cần điều chỉnh các tham số theo hướng ngược lại với gradient.
Công thức cập nhật tham số:
[ \theta = \theta – \alpha \nabla J(\theta) ]
Trong đó:
- (\theta) là vector tham số của mô hình.
- (\alpha) là tỷ lệ học (learning rate).
- (\nabla J(\theta)) là gradient của hàm mất mát.
Các yếu tố ảnh hưởng đến gradient descent:
- Tỷ lệ học: Tỷ lệ học quá cao có thể dẫn đến việc không hội tụ, trong khi tỷ lệ học quá thấp có thể làm chậm quá trình tối ưu hóa.
- Số lượng mẫu: Sử dụng tất cả các mẫu trong mỗi lần cập nhật tham số có thể làm cho quá trình chậm hơn.
- Độ phức tạp của mô hình: Mô hình phức tạp hơn có thể cần nhiều thời gian hơn để tối ưu hóa.
5.2 Các biến thể của gradient descent
Có nhiều biến thể của gradient descent được phát triển để cải thiện hiệu suất và tốc độ hội tụ. Dưới đây là một số biến thể phổ biến:
| Biến thể | Mô tả |
|---|---|
| Batch Gradient Descent | Sử dụng toàn bộ dữ liệu để tính toán gradient trước khi cập nhật tham số. |
| Stochastic Gradient Descent (SGD) | Cập nhật tham số sau mỗi mẫu, giúp tăng tốc độ hội tụ nhưng có thể gây ra dao động. |
| Mini-batch Gradient Descent | Kết hợp giữa hai phương pháp trên, sử dụng một tập mẫu nhỏ để tính toán gradient. |
| Momentum | Thêm một yếu tố động lực để giúp vượt qua các điểm tối ưu cục bộ. |
| Adam | Kết hợp giữa RMSProp và Momentum, tự động điều chỉnh tỷ lệ học. |
Lợi ích của các biến thể:
- Tăng tốc độ hội tụ: Các biến thể như SGD và Mini-batch giúp giảm thời gian tính toán.
- Giảm dao động: Các phương pháp như Momentum giúp làm mượt quá trình tối ưu hóa.
- Tự động điều chỉnh: Adam tự động điều chỉnh tỷ lệ học, giúp tối ưu hóa dễ dàng hơn.
5.3 Kỹ thuật tối ưu hóa để cải thiện hiệu suất mô hình
Để cải thiện hiệu suất của mô hình khi sử dụng gradient descent, có một số kỹ thuật tối ưu hóa có thể áp dụng:
- Sử dụng tỷ lệ học thích ứng: Các thuật toán như Adam hay RMSProp tự động điều chỉnh tỷ lệ học theo từng tham số.
- Regularization: Thêm các thuật toán như L1 hoặc L2 regularization để giảm thiểu hiện tượng overfitting.
- Early Stopping: Dừng quá trình huấn luyện khi hàm mất mát trên tập kiểm tra không còn giảm nữa.
- Batch Normalization: Giúp ổn định và cải thiện tốc độ huấn luyện bằng cách chuẩn hóa đầu vào của mỗi lớp.
Bảng so sánh các kỹ thuật tối ưu hóa:
| Kỹ thuật | Mô tả | Lợi ích |
|---|---|---|
| Tỷ lệ học thích ứng | Điều chỉnh tỷ lệ học theo từng tham số. | Tăng tốc độ hội tụ. |
| Regularization | Giảm thiểu overfitting. | Cải thiện khả năng tổng quát. |
| Early Stopping | Dừng huấn luyện khi không còn cải thiện. | Tiết kiệm thời gian huấn luyện. |
| Batch Normalization | Chuẩn hóa đầu vào của mỗi lớp. | Giúp ổn định và cải thiện tốc độ. |
Kết luận
Tối ưu hóa gradient descent là một phần quan trọng trong học sâu, và việc hiểu rõ nguyên lý hoạt động cũng như các biến thể và kỹ thuật tối ưu hóa sẽ giúp cải thiện hiệu suất của mô hình. Bằng cách áp dụng các kỹ thuật này, các nhà nghiên cứu và kỹ sư có thể xây dựng các mô hình học sâu hiệu quả hơn, đáp ứng tốt









